Abstract
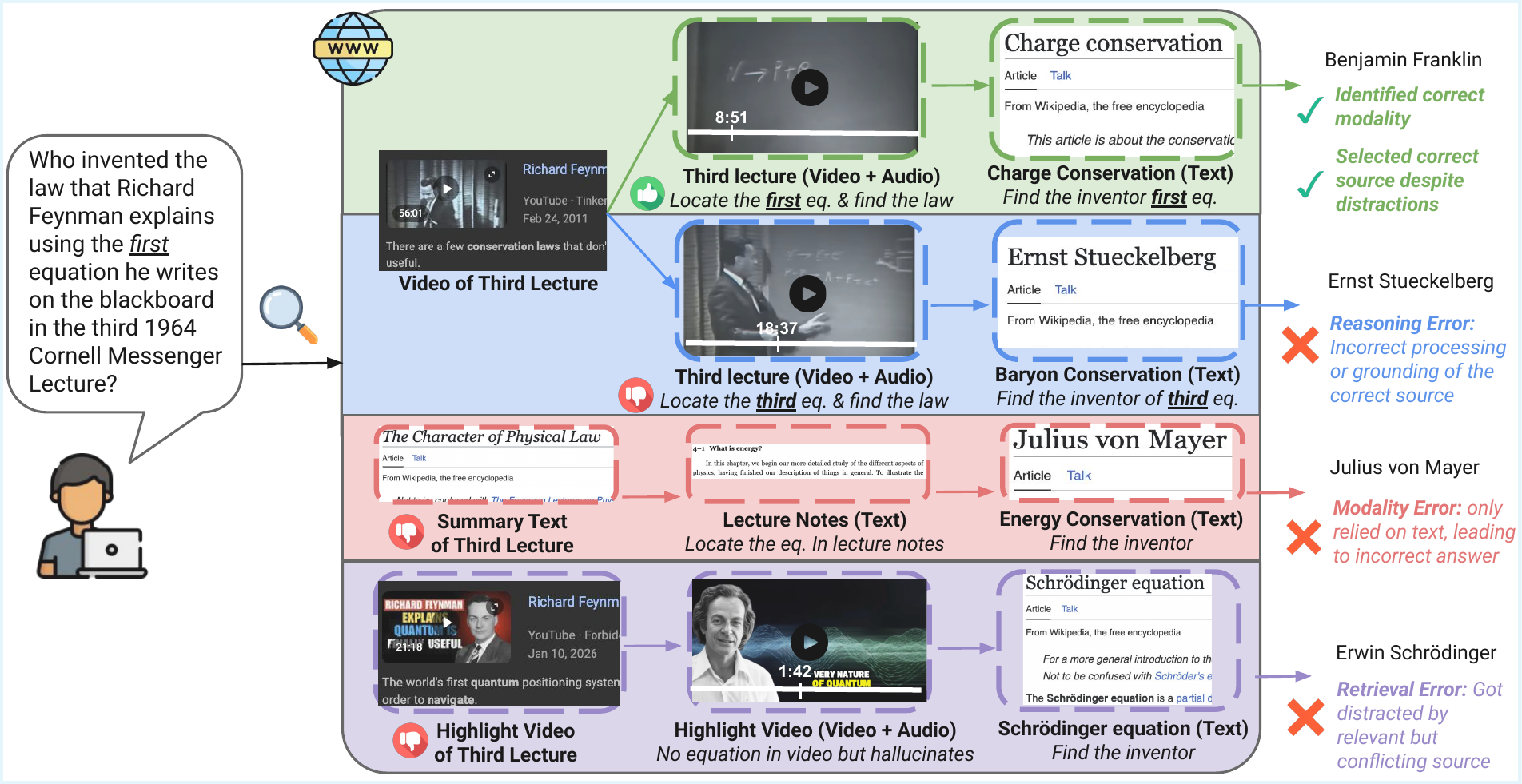
Motivated by the underspecified, multi-hop nature of search queries and the multimodal, heterogeneous, and often conflicting nature of real-world web results, we introduce MERRIN (Multimodal Evidence Retrieval and Reasoning in Noisy Web Environments), a human-annotated benchmark for evaluating search-augmented agents.
MERRIN measures AI agents' ability to identify relevant modalities, retrieve multimodal evidence, and perform multi-hop reasoning over noisy web sources.
It differs from prior work in three important aspects: (1) using natural language queries without explicit modality cues, (2) incorporating underexplored modalities such as video and audio, and (3) requiring the retrieval of complex, often noisy or conflicting multimodal evidence during web search.
We evaluate diverse search agents powered by ten models, including strong closed-source models (e.g., GPT-5.4-mini, Gemini 3/3.1 Flash/Pro) and open-weight models (Qwen3-4B/30B/235B), across three search settings (no search, native search, and agentic search).
Our results show that MERRIN is highly challenging: the average accuracy across all agents is 22.3%, with the best-performing agent reaching only 40.1%.
We further observe that while stronger agents like Gemini Deep Research achieve higher performance, gains are modest due to over-exploration; they take more steps and use more tools, but are often distracted by conflicting or partially relevant web content, leading to incorrect answers.
Our analysis of agent bottlenecks shows that while both search effectiveness and multimodal reasoning remain critical challenges, reasoning is the more pressing limitation.
Compared to humans, these agents consume more resources yet achieve lower accuracy, largely due to inefficient source selection and an overreliance on text modalities.
These findings highlight the need for search agents capable of robust search and reasoning across diverse modalities in noisy web environments, making MERRIN a valuable testbed for evaluating such capabilities.